
I'm trying to figure out how to do a natural language query (nlq) that uses the hierarchical and relational structure found in an ontology to return documents that are semantically related to the query, nlq triples which are instances of the ontologies used, and a graph of these instances in addition to related triples by SPARQL that use the subject or object of the nlq triples as the subject. Below is a query result of results from the query "Car Projects with Brent Shambaugh".
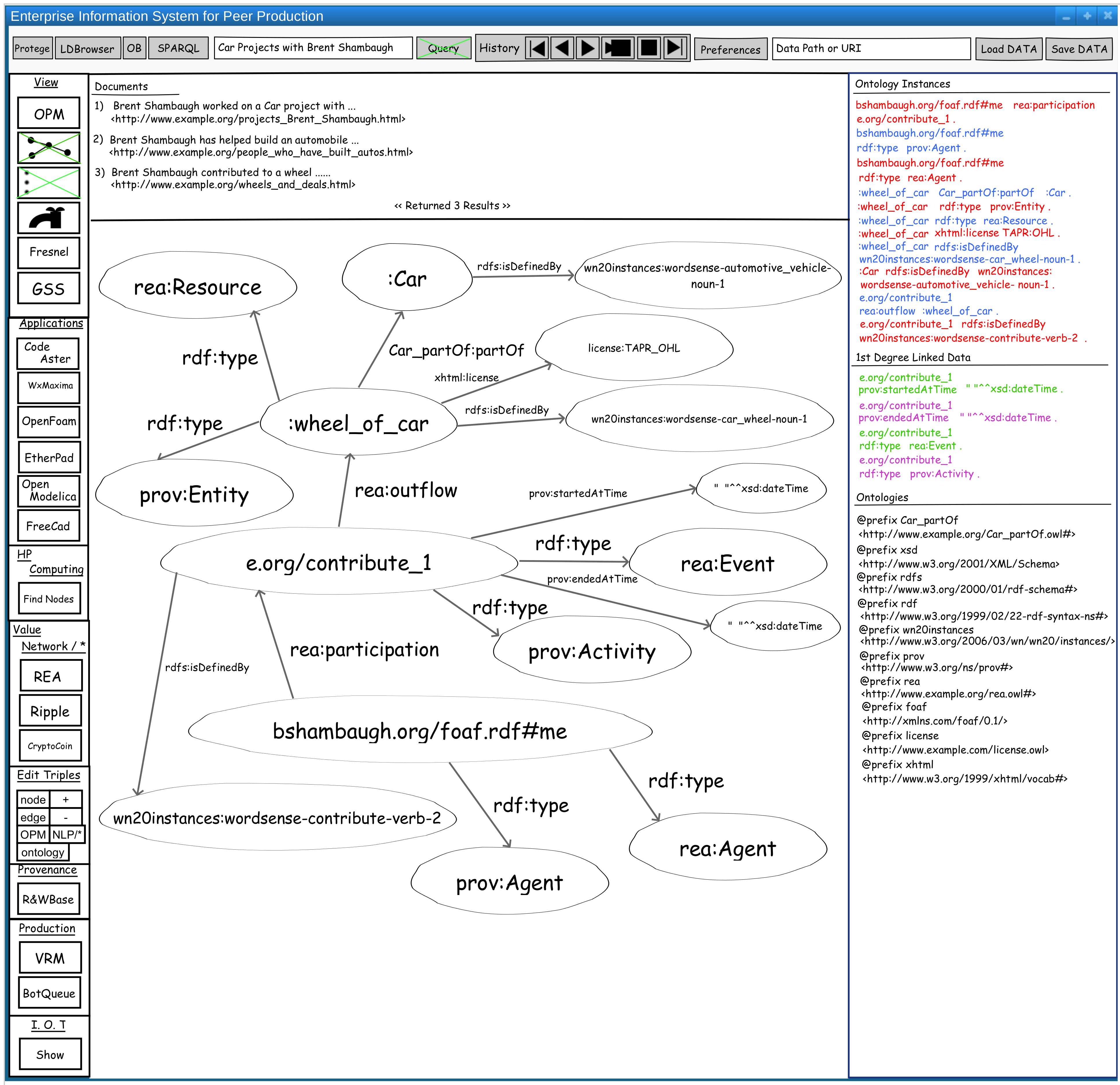
What I really want most is something like: this query contains terms that are described by these ontologies, and the terms are described by these triples.
I think I might be able to back this out of the query in this Sanchez's work, even though its aim was to get documents.
At the moment, I know typical search uses TFIDF. I know this from taking a Big Data (or at least starting) course in 2013. I also found a book called Mining Massive DataSets that contains a lot of the information from the course (http://infolab.stanford.edu/~ullman/mmds/book.pdf). Understanding it makes sense. Up to this point, I've struggled implementing it, resorting to things like Lucene and Solr coupled with Stanbol for nlp (this works for tagging). Fortunately, within the past few weeks I discovered Daniel Shiffman's coding rainbow videos. He explains how to do TFIDF (Coding Challenge $40.3: TF-IDF) https://www.youtube.com/watch?v=RPMYV-eb6lI .
I explored how to implement a search engine and I came across some blog posts by Arden Dertat :
How to Implement a Search Engine Part 1: Create Index
How to Implement a Search Engine Part 2: Query Index
How to Implement a Search Engine Part 3: Ranking tf-idf
He gives some links to his code.
Mr. Dertat also references a book on Information Retrieval: (http://nlp.stanford.edu/IR-book/information-retrieval-book.html)
Look at the implementation of TFIDF by Shiffman, then the implementation of a search engine by Dertat. The second will require knowledge of Python, but it is easy to learn and it will be useful understanding the code for the semantic web tutorial (http://www.w3.org/2000/10/swap/doc).
ReplyDelete